
Clustering has primarily been used as an analytical technique to group unlabeled data for extracting meaningful information. The fact that no clustering algorithm can solve all clustering problems has resulted in the development of several clustering algorithms with diverse applications. We review data clustering, intending to underscore recent applications in selected industrial sectors and other notable concepts. In this paper, we begin by highlighting clustering components and discussing classification terminologies. Furthermore, specific, and general applications of clustering are discussed. Notable concepts on clustering algorithms, emerging variants, measures of similarities/dissimilarities, issues surrounding clustering optimization, validation and data types are outlined. Suggestions are made to emphasize the continued interest in clustering techniques both by scholars and Industry practitioners. Key findings in this review show the size of data as a classification criterion and as data sizes for clustering become larger and varied, the determination of the optimal number of clusters will require new feature extracting methods, validation indices and clustering techniques. In addition, clustering techniques have found growing use in key industry sectors linked to the sustainable development goals such as manufacturing, transportation and logistics, energy, and healthcare, where the use of clustering is more integrated with other analytical techniques than a stand-alone clustering technique.
Avoid common mistakes on your manuscript.
Clustering has been defined as the grouping of objects in which there is little or no knowledge about the object relationships in the given data (Jain et al. 1999; Liao 2005; Bose and Chen 2015; Grant and Yeo 2018; Samoilenko and Osei-Bryson 2019; Xie et al. 2020). Clustering also aims to reveal the underlying classes present within the data. Besides, clustering is referred to as a technique that groups unlabeled data with little or no supervision into different classes. The grouping is such that objects that are within the same class have similarity characteristics and are different from objects within other classes. Clustering has also been described as an aspect of machine learning that deals with unsupervised learning. The learning lies in algorithms extracting patterns from datasets obtained either from direct observation or simulated data. Schwenker and Trentin (2014) described the learning process as attempts to classify data observations or independent variables without knowledge of a target variable.
The grouping of objects into different classes has been one of the outcomes of data clustering over the years. However, the difficulty of obtaining a single method of determining the ideal or optimal number of classes for several clustering problems has been a key clustering issue noted by several authors such as Sekula et al. (2017), Rodriguez et al. (2019), Baidari and Patil (2020). Authors have referred to this issue as the subjectivity of clustering. Sekula et al. (2017), Pérez-Suárez et al. (2019) and Li et al. (2020a) described this subjectivity as the difficulty in indicating the best partition or cluster. The insufficiency of a unique clustering technique in solving all clustering problems would imply the careful selection of clustering parameters to ensure suitability for the user of the clustering results. Jain et al. (1999) specifically noted the need for several design choices in the clustering process which have the potential for the use and development of several clustering techniques/algorithms for existing and new areas of applications. They presented general applications of clustering such as in information filtering and retrieval which could span across several industrial/business sectors. This work however discusses applications of clustering techniques specifically under selected industrial/business sectors with strong links to the United Nations Sustainable Development Goals (SDGs). We also note some new developments in clustering such as in techniques and datatype over the years of the publication of Jain et al. (1999).
This review aims to give a general overview of data clustering, clustering classification, data concerns in clustering, application and trends in the field of clustering. We present a basic description of the clustering component steps, clustering classification issues, clustering algorithms, generic application of clustering across different industry sectors and specific applications across selected industries. The contribution of this work is mainly to underscore how clustering is being applied in industrial sectors with strong links to the SDGs. Other minor contributions are to point out clustering taxonomy issues, and data input concerns and suggest the size of input data is useful for classifying clustering algorithms. This review is also useful as a quick guide to practitioners or users of clustering methods interested in understanding the rudiments of clustering.
Clustering techniques have predominantly been used in the field of statistics and computing for exploratory data analysis. However, clustering has found a lot of applications in several industries such as manufacturing, transportation, medical science, energy, education, wholesale, and retail etc. Furthermore, Han et al. (2011), Landau et al. (2011), and Ezugwu et al. (2022) indicated an increasing application of clustering in many fields where data mining or processing capabilities have increased. Besides, the growing requirement of data for analytics and operations management in several fields has increased research and application interest in the use of clustering techniques.
To keep up with the growing interest in the field of clustering over the years, general reviews of clustering algorithms and approaches have been observable trends (Jain et al. 1999; Liao 2005; Xu and Wunsch 2005; Alelyani et al. 2013; Schwenker and Trentin 2014; Saxena et al. 2017). Besides, there has been a recent trend of reviews of specific clustering techniques such as in Denoeux and Kanjanatarakul (2016), Baadel et al. (2016) Shirkhorshidi et al. (2014), Bulò and Pelillo (2017), Rappoport and Shamir (2018), Ansari et al. (2019), Pérez-Suárez et al. (2019), Beltrán and Vilariño (2020), Campello et al. (2020). We have also observed a growing review of clustering techniques under a particular field of application such as in Naghieh and Peng (2009), Xu and Wunsch (2010), Anand et al. (2018), Negara and Andryani (2018), Delgoshaei and Ali (2019). However, there appears not to be sufficient reviews targeted at data clustering applications discussed under the Industrial sectors. The application of clustering is vast, and as Saxena et al. (2017) indicated, might be difficult to completely exhaust.
To put this article into perspective, we present our article selection method, a basic review of clustering steps, classification and techniques discussed in the literature under Sect. 2. Furthermore, we discuss clustering applications across and within selected business sectors or Industries in Sect. 3. A trend of how clustering is being applied in these sectors is also discussed in Sect. 3. In Sect. 4 we highlight some data issues in the field of clustering. Furthermore, in Sect. 5, we attempt to discuss and summarize clustering concepts from previous sections. We thereafter conclude and suggest future possibilities in the field of data clustering in Sect. 6.
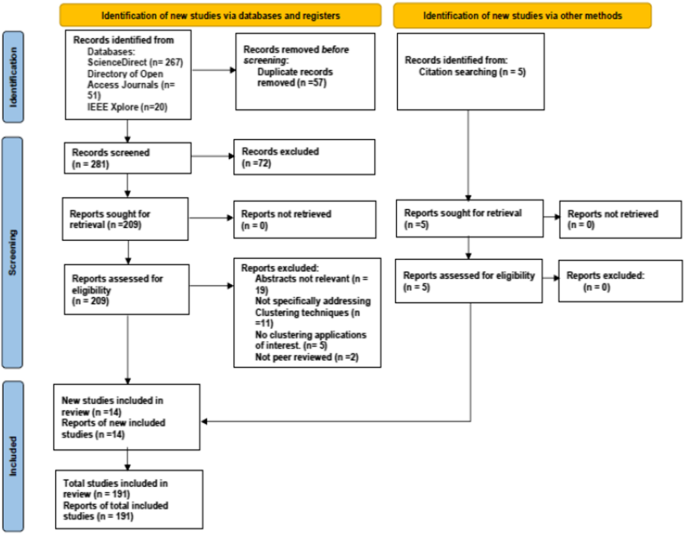
Our article selection in this work follows a similar literature search approach of Govender and Sivakumar (2020) where google scholar (which provides indirect links to databases such as science direct) was indicated as the main search engine. In addition to key reference word combinations, they used such as "clustering", "clustering analysis”, we searched the literature using google scholar for clustering techniques", "approaches", "time series", "clustering sector application", "transportation", "manufacturing", “healthcare” and “energy”. More search was conducted using cross-referencing and the screening of abstracts of potential articles. We ensured that the articles with abstracts containing the keywords earlier indicated were selected for further review while those not relevant to our clustering area of focus were excluded. Figure 1 below further illustrates the process of our article selection using the Prisma flow diagram (Page et al. 2021) which aims to show the flow of information and summary of the screening for different stages of a systematic review.
The components of data clustering are the steps needed to perform a clustering task. Different taxonomies have been used in the classification of data clustering algorithms Some words commonly used are approaches, methods or techniques (Jain et al. 1999; Liao 2005; Bulò and Pelillo 2017; Govender and Sivakumar 2020). However, clustering algorithms have the tendency of being grouped or clustered in diverse ways based on their various characteristics. Jain et al. (1999) described the tendency to have different approaches as a result of cross-cutting issues affecting the specific placement of clustering algorithms under a particular approach. Khanmohammadi et al. (2017) noted these cross-cutting issues as a non-mutual exclusivity property of clustering classification. We follow the logical perspective of Khanmohammadi et al. (2017) using the term criteria to classify data clustering techniques or approaches. The clustering techniques or approaches are subsequently employed to classify clustering algorithms.
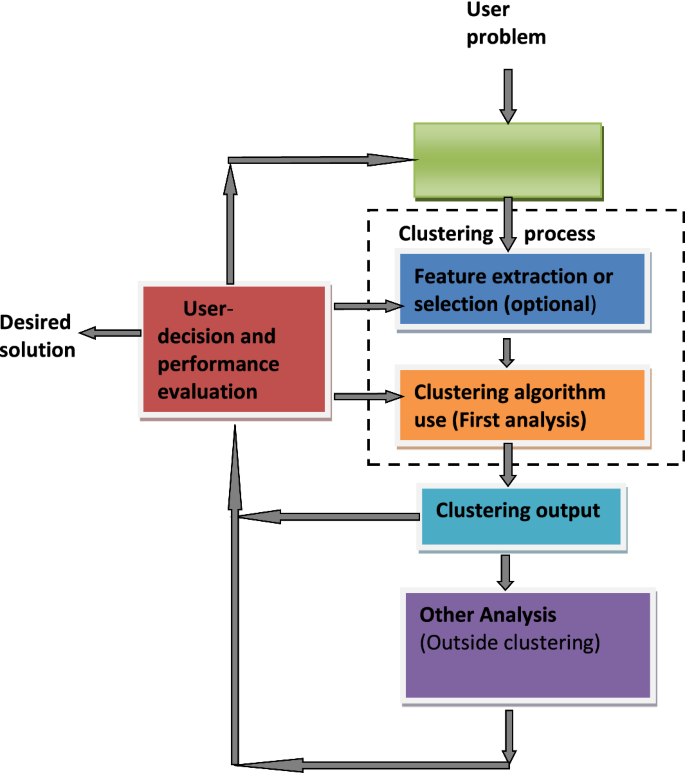
Components of data clustering have been presented as a flow from data samples requirement through clustering algorithms to cluster formations by several authors such as Jain et al. (1999), Liao (2005), and Xu and Wunsch (2010). According to Jain et al. (1999), the following were indicated as the necessary steps to undertake a clustering activity: pattern representation (feature extraction and selection), similarity computation, grouping process and cluster representation. Liao (2005) suggested three key components of time series clustering which are the clustering algorithm, similarity/dissimilarity measure and performance evaluation. Xu and Wunsch (2010) presented the components of a clustering task as consisting of four major feedback steps. These steps were given as feature selection/extraction, clustering algorithm design/selection, cluster validation and result interpretation. According to Alelyani et al. (2013) components of data clustering was illustrated as consisting of the requirement of unlabeled data followed by the operation of collating similar data objects in a group and separation of dissimilar data objects into other groups. Due to the subjective nature of clustering results, the need to consider performance evaluation of any methods of clustering used has become necessary in the steps of clustering.
Taking these observations into consideration, we essentially list steps of clustering activity below and present them also in Fig. 2:
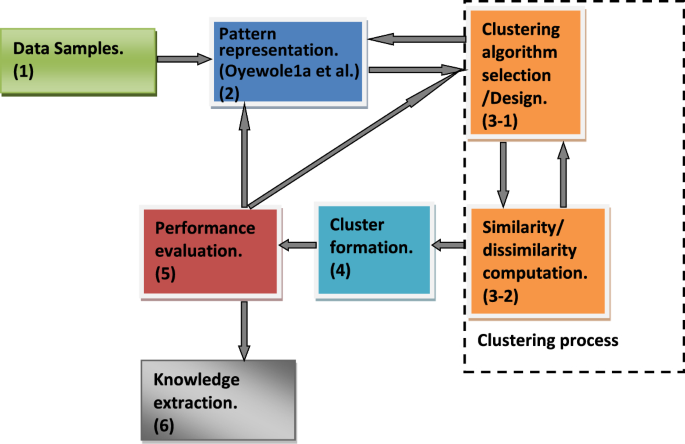
Out of the six steps highlighted above, component steps (2), (3), and (5) practically appear to be critical. This is because if the components steps (2), (3), and (5) are not appropriately and satisfactorily conducted during clustering implementation, each step or all steps (2), (3) (5) including (4) might need to be revisited. We briefly discuss these vital steps.
Jain et al. (1999) defined pattern representation as the "number of classes, the number of available patterns, and the number, type, and scale of the features available to the clustering algorithm". They indicated that pattern representation could consist of feature extraction and/or selection. On one hand, feature selection was defined as “the process of identifying the most effective subset of the original features to use in the clustering process”. On the other hand, “feature extraction is the use of one or more transformations of the data input features to produce new salient features to perform the clustering or grouping of data.” We refer readers to Jain et al. (1999), Parsons et al. (2004), Alelyani et al. (2013), Solorio-Fernández et al. (2020) for a comprehensive review of pattern representation, feature selection and extraction.
This step is essentially described as the grouping process by Jain et al. (1999) into a partition of distinct groups or groups having a variable degree of membership. Jain et al. (1999) noted that clustering techniques attempt to group patterns so that the classes thereby obtained reflect the different pattern generation processes represented in the pattern set. As noted by Liao (2005) clustering algorithms are a sequence of procedures that are iterative and rely on a stopping criterion to be activated when a good clustering is obtained. Clustering algorithms were indicated to depend both on the type of data available and the particular purpose and application. Liao (2005) discussed similarity/dissimilarity computation as the requirement of a function used to measure the similarity between two data types (e.g., raw values, matrices, features-pairs) being compared. Similarly, Jain et al. (1999) presented this as a distance function defined on a pair of patterns or groupings. Several authors such as Jain et al. (1999), Liao (2005), Xu and Wunsch (2010), Liu et al. (2020) have noted that similarity computation is an essential subcomponent of a typical clustering algorithm. We further discuss some similarity/dissimilarity measures in Sect. 2.4.
This step is done to confirm the suitability of the number of clusters or groupings obtained as the results of clustering. Liao (2005) discussed this as validation indices or functions to determine the suitability or appropriateness of any clustering results. Sekula et al. (2017) indicated that the high possibility of clustering solutions is dependent on the validation indices used and suggests the use of multiple indices for comparison.
There have been different terminologies for data clustering classification in the literature. This variety of classifications was indicated by Samoilenko and Osei-Bryson (2019), Rodriguez et al. (2019) as a means to organize different clustering algorithms in the literature. Some have used the word approaches, methods, and techniques. However, the term techniques and methods appear to have been widely used to depict the term clustering algorithms.
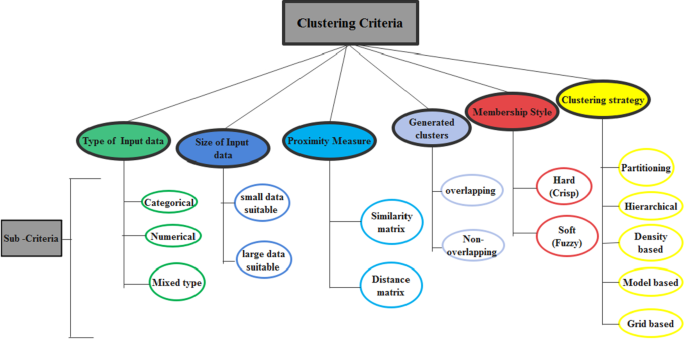
Liao (2005) segmented time-series data clustering using three main criteria. These criteria referred to the manner of handling data as either in its raw form or transforming the raw data into a feature or parameters of a model. Saxena et al. (2017) used the terminology of clustering approaches and indicated linkage to the reason for different clustering techniques. This is due to the reason for the word “cluster” not having an exact meaning for the word. Bulò and Pelillo (2017) also discussed the limitation of hard or soft classifications of clustering into partitions and they suggested an approach to clustering which was referred to as the game-theoretic framework that simultaneously overcomes limitations of the hard and soft partition approach of clustering. Khanmohammadi et al. (2017) indicated five criteria in the literature for classifying clustering algorithms which are the nature of data input, the measure of proximity of data objects, generated data cluster, membership function style and clustering strategy. These criteria have resulted in different classifications of clustering algorithms.
We present in Fig. 3 below a summary of the classification criteria presented by Khanmohammadi et al. (2017). We extend the classification criteria by adding a criterion that can also be used to classify clustering algorithms. This is the size of input data. The size of data was presented as a factor that affects the selection of clustering algorithm by Andreopoulos et al. (2009), Shirkhorshidi et al. (2014) and more recently Mahdi et al. (2021). They observed that some clustering algorithms perform poorly and sacrifice quality when the size of data increases in volume, velocity, variability and variety. On another hand, some other clustering algorithms can increase scalability and speed to cope with the huge amount of data. Another possible criterion that could be added is what Bulò and Pelillo (2017) described as a framework for clustering. However, this appears to be a clustering strategy. They described this as a perspective framework of the clustering process that is different from the traditional approaches of obtaining the number of clusters as a by-product of partitioning. They referred to this as a clustering ideology which can be thought of as a sequential search for structures in the data provided. Figure 3 below categorizes the approaches or criteria and the sub-approaches or sub-criteria that can be useful in classifying clustering algorithms.
The criteria/sub-criteria described in the previous section can be used in classifying clustering algorithms. However, clustering algorithms have traditionally been classified as either having a partitioning (clusters obtained are put into distinctive groups) or hierarchical (forming a tree linkage or relationships for the data objects being grouped) strategy to obtain results. Jain et al. (1999) indicated the possibility of having additional categories to the traditional classification. Some authors have since then indicated the classification of clustering algorithms using five clustering strategies such as in Liao (2005), Han et al. (2011). Using the clustering criteria described earlier we demonstrate the classification of selected 21 clustering algorithms out of several clustering algorithms in the literature. These are (1) k-means, (2) k-mode, (3) k-medoid, (4), Density-Based Spatial Clustering of Applications with Noise (DBSCAN), (5) CLustering In QUEst (CLIQUE), (6) Density clustering (Denclue), (7) Ordering Points To Identify the Clustering Structure (OPTICS), (8) STatistical INformation Grid (STING), (9) k-prototype, (10) Autoclass (A Bayesian approach to classification) (11) fuzzy k-means, (12) COOLCAT (An entropy based algorithm for categorical clustering), (13) Cluster Identification via Connectivity Kernels (CLICK), (14) RObust Clustering using linK (Sandrock), (15) Self Organising Map (SOM), (16) Single-linkage (17) Complete-linkage (18) Centroid-linkage, (19) Clustering Large Applications Based upon Randomized Search (CLARANS), (20) Overlapped k-means, (21) Model-based Overlapping Clustering (MOC).
We summarize these classifications in Tables 1 and 2 below and include selected references for extensive reading.
One of the approaches earlier listed for classifying clustering algorithms is the type of input data. Liao (2005) observes that the data that can be inputted into any clustering task can be classified as binary, categorical, numerical, interval, ordinal, relational, textual, spatial, temporal, spatio-temporal, image, multimedia, or mixtures of the above data types. This classification can also be sub-classified. For example, numeric raw data for clustering can either be static, time series or as a data stream. Static data do not change with time while time-series data have their data objects changing with time. Aggarwal et al. (2003) described data stream as large volumes of data arriving at an unlimited growth rate. As noted by Mahdi et al. (2021) data types that are vast and complex to store such as social network data (referred to as big data) and high-speed data (data stream) such as web-click streams, network traffic could be challenging to cluster. In addition, they emphasized that the type of data type considered often influences the type of clustering techniques selected.
The application of some clustering algorithms directly to raw data has been noted to be an issue as the data size becomes larger (Gordon 1999; Parsons et al. 2004). Two reasons were given for this observed problem. The first reason indicated was based on the type of clustering algorithm used. This is such that some clustering algorithms fully take into consideration all dimensions of the data during the clustering process. As a result, they conceal potential clusters of outlying data objects. The second was because, as dimensionality increases in the given data, the distance measure for computing similarity or dissimilarity among data objects becomes less effective. Feature extraction and selection were suggested as a generic method to solve this problem by reducing the dimensionality of the data before the clustering algorithms are applied. However, they noted that this feature-based method could omit certain clusters hidden in subspaces of the data sets. Subspace clustering was the method suggested to overcome this.
Research in the field of reducing the dimensionality of the original data through feature extraction and selection methods and variants such as subspace clustering has continued to be investigated by several authors (Huang et al. 2016; Motlagh et al. 2019; Solorio-Fernández et al. 2020). Huang et al. (2016) specifically indicated time-series data to be subject to large data sizes, high dimensionality, and progressive updating. They suggested the preference of clustering over time segments of time-series data compared to the whole time-series sequence to ensure all hidden clusters in the time series data are accounted for. Hence data pre-processing techniques such as (normalization, cumulative clustering etc.) have been suggested. Pereira and Frazzon (2020) utilized data preprocessing to detect and remove outliers followed by normalization before a clustering algorithm was applied. Li et al. (2020a) considered ameliorating datasets to improve clustering accuracy by transforming bad data sets into good data sets using the HIBOG. Solorio-Fernández et al. (2020) presents a comprehensive review of feature selection to highlight the growing advances of unsupervised feature selection methods (filter, wrapper and hybrid) for unlabeled data.
Clustering of data could also become an issue when multi-source and multi-modal data are considered. Multi-source data (originating from several sources) have been observed with characteristics such as complexity, heterogeneity, dynamicity, distribution and largeness (Uselton et al. 1998). As noted by Sprague et al. (2017) and Afyouni et al. (2021) the combination or fusion of data from diverse organizations having different reporting formats, structures and dimensions could present some complexities in multi-source data. Lahat et al. (2015) and Li and Wang (2021) discussed the complementary and diverse attributes of multi-modal data (e.g. the same data from text, image audio, and video) and also provided similar challenges of complexity resulting from the fusion of such data. Adaptation of existing clustering algorithms or development of new clustering algorithms will become useful to analyze such potential big and complex data.
Since clustering results are strongly linked to the type and features of the data being represented, their performance is being improved through current supervised machine learning methods such as Deep Neural Networks (DNN). As noted by James et al. (2015) and Ni et al. (2022), DNN have had more successful performance (e.g. in speech and text modelling, video and image classification) compared to the earlier developed neural networks as seen in (Hastie et al. 2009) due to the less training tinkering required and increasing availability of large training data sets. DNN could be used to obtain improved feature representation useful for clustering before the actual clustering is performed. This has been referred to as deep clustering in the machine learning field (Aljalbout et al. 2018). According to Min et al. (2018) emphasis was placed on prioritizing network architecture over clustering loss in classifying deep clustering due to the basic desire for clustering-oriented representations. They further classified deep clustering based on: (I) the use of Autoencoder (AE) to obtain the feasible feature representation (II) Feedforward networks such as Feedforward convolutional networks which can use specific clustering loss to obtain feasible feature representation (III) Generative Adversarial Network (GAN) and Variational Autoencoder (VAE) which uses effective generative learning frameworks to obtain feature representations.
In this section, we highlight the major considerations in the earlier sections and project possible application trends in the field of clustering. In Sect. 2, we noted some inconsistencies in terminologies and classification criteria used in grouping clustering algorithms and their variants. Authors in the field of data clustering have suggested different terminologies for group clustering algorithms. The partitioning and hierarchical approaches have primarily been used to group clustering algorithms. Other approaches such as density-based, model-based, and grid-based have been suggested as an extension to the primary approaches. The classification of the five clustering approaches earlier mentioned can be categorized as clustering strategies. Other clustering criteria such as proximity measure, input data, size of input data, membership function style, and generated clusters can further be used to categorize different approaches employed in classifying clustering algorithms. The selection and design of clustering algorithms are observed to be a vital step in the clustering components. We suggest that the clustering component steps tend towards being cyclical with feedback than a straight follow. This relates more with the reality of iteration in obtaining the appropriate cluster results.
The reality is that there is no universally accepted clustering algorithm to solve all clustering problems (Jain et al. 1999; Rodriguez et al. 2019) and the limitation of clustering algorithms is a strong motivation for the emergence of new clustering algorithms or variants of the traditional clustering algorithms. As new clustering algorithms emerge, it is expected that existing terminologies and classification approaches could become broader with a seeming departure from the traditional approaches. With the growing number of clustering algorithms is also the growing number of clustering validation indices. This perhaps is due to the reason that users of clustering results are more interested in knowing with good confidence that clustering results obtained are well suited for the application. To test the suitability of different clustering algorithms and indices in meeting the users' needs and also due to the increase in computing technological capabilities, clustering algorithms and indices are being combined in computer programs. Rodriguez et al. (2019) presented a comparative study of 9 clustering algorithms available in the R programming language. Other authors such as Sekula (2015) have indicated some clustering packages in the R-programming language that can be useful for comparison and as a friendly user application. Besides, computer programs are used to suggest a suitable number of clusters for clustering algorithms (e.g. k-means) requiring an input of clusters as applied by (Rhodes et al. 2014; Charrad et al. 2015).
In Sect. 3, we considered that the application of clustering has largely been reported in areas such as image segmentation, object recognition, character recognition, information retrieval, and data mining. We have considered these areas to be specific applications of clustering algorithms. It is expected that more field applications will be reported due to the vast applicability of clustering techniques. Also emphasized is the application of clustering in selected industrial sectors. We specifically noted the diverse classification schemes and groupings of industrial sectors. The numerous clustering algorithms in existence have the corresponding possible applicability in several of these industries. We, however, selected manufacturing, energy, transportation and logistics, and healthcare as examples to illustrate the application of clustering in industries with important links to achieving sustainable development goals. The application of clustering techniques in these industries appears to be a move from a stand-alone analytical technique into hybrid techniques with other analytical processes. This suggests that clustering techniques will continue to be relevant as an integrated analytical technique in different industries and sectors. Besides, the vast application of clustering techniques will imply practitioners or users with a basic understanding of clustering techniques can use the clustering algorithm embedded into the software with little difficulty.
In Sect. 4, we highlighted some data sources used in clustering and discussed some data issues users of clustering techniques are likely to deal with. Clustering raw data inputs are generally observed to be more problematic than refined data inputs. This is attributable to the dimensionality problem. Due to the increase in computing technology for many industrial applications and cloud computing, the use of clustering techniques to analyze high volumes of static, time-series, multi-sources, and multimodal data are trends in the future. For multi-sources and multimodal data, applications or frameworks that can effectively integrate or fuse the complementary attributes of such data are currently observable trends. As such clustering techniques will be more readily deployed in such secondary data-use domain.
As the size of data becomes larger due to modern data mining capabilities and the need to avoid incomplete knowledge extraction from single sources or modes of data, methods that fuse complementary and diverse data with a goal of understanding and identifying hidden clusters are also notable trends. For example, deep learning methods are sometimes merged with traditional clustering methods to further search for underlying clusters and thereby improve clustering performance.
Putting the main observations in this paper together, the emergence of new clustering algorithms is expected due to the subjectivity nature of clustering and its vast applicability in diverse fields and industries. This suggests that emerging scholars can find meaningful research interest in several aspects of data clustering such as the development of new clustering algorithms, validity indices, improving clustering quality and comprehensive field and industry reviews of clustering techniques. Industry Practitioners will also find use in the application of specific clustering algorithms to analyze unlabeled data to extract meaningful information.
In this paper, we presented a basic definition and description of clustering components. We extended existing criteria in the literature for classifying clustering algorithms. Both traditional clustering algorithms and emerging variants were discussed. Also emphasized is the reality that clustering algorithms could produce different groupings for a given set of data. Also, as no clustering algorithm can solve all clustering problems, several clustering validation indices are used and have also been developed to gain some confidence in the cluster results obtained from clustering algorithms.
We summarized field applications of clustering algorithms such as in image segmentation, object recognition, character recognition, data mining and social networking that have been pointed out in the literature. Selected applications of clustering techniques and notable trends in industrial sectors with strong links to achieving sustainable development goals were further presented to show the diverse application of clustering techniques. Also suggested are possible application trends in the field of clustering that are observable from both specific and general article reviews in the literature. Some data input concerns in the field of clustering were examined.
This study presents a foundation for other research work that can be projected from it. Firstly, the investigation into feature extraction, selection, alignment, and other methods that could reveal hidden clusters in large volumes, high-frequency data such as data streams, multi-modal and multi-source data obtainable from current data mining capabilities, technologies and computer simulations are current and research interest into the future for the academia and industry.
In addition, the development of new clustering strategies to analyze existing and modern data types (e.g., fused multi-source and multi-modal data) would also be of more interest to researchers. The outputs and knowledge extracted from such data types could be beneficial to policymakers and business practitioners in informed decision making.
Secondly, the use of clustering techniques has a high possibility of finding more applicability in existing fields. Examples are text mining, industrial big data applications, biomedicals, commercial sectors, military applications, space navigation and biological processes. In emerging areas of applications such as Learning management systems and social media that currently churn out huge amounts of data and have recently seen a further increase due to the covid-19 pandemic, the development of effective and efficient clustering algorithms to sufficiently mine the massive amount of data from such fields are currently being projected. Deep clustering will generally find more applications in analysis useful across different business sectors where pure clustering methods have been used. This will be due to observed performance in obtaining better clustering results for example in image classification where the Feedforward convolutional network has been very useful.
Finally, a data clustering trend that summarizes trends from qualitative and quantitative results of the application of diverse variants of clustering strategies will adequately be an improvement on this research efforts.
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.


